Lambda--C++
参见这里
今天写完博客后部署至github时,老是报错。如下图所示:
ping github.com如下图所示: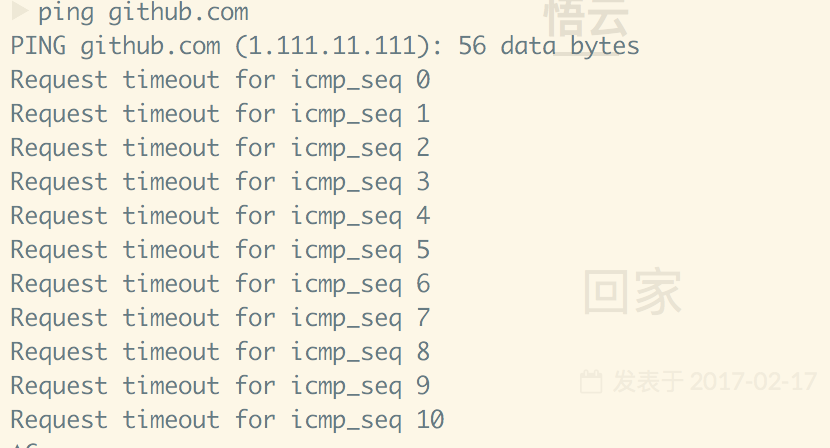
更改host文件之后,可正常部署。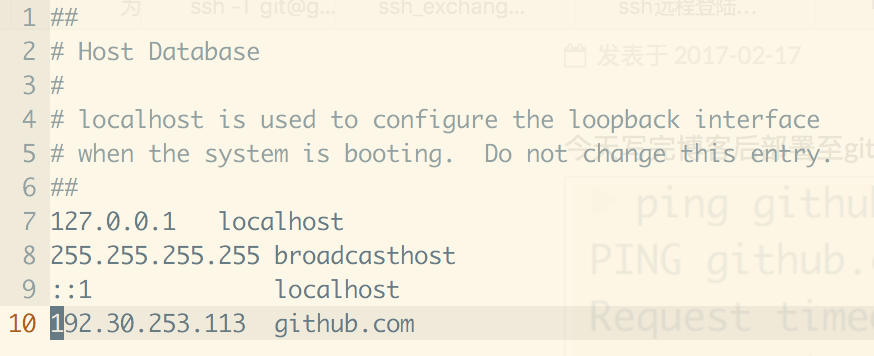
距离上次回家已经一年了,放假之后意兴阑珊,买了车票就踏上了回家的路。
第一件事就是前往驾校继续学习科目三,每天早上六点半去驾校,冷!师傅是个好人,了解到我时间很紧的情况之后,将已经安排的三个名额让出一个给我,非常感谢!学车的时候师傅天天吼我,但是无所谓~ 我把所有能犯的错都犯了两遍最后完美通过考试。
考试之余就是玩游戏以及打麻将了,哈哈,带回来的书一次也没看!老家的小伙伴一直在催我回去打牌,科目三过了之后迫不及待回到老家。早上打,下午打,晚上打。今年玩的血战,技术不行,运气不行,带回家的两千五输完了,哈哈。
今年结婚的亲戚特别多,连着三四天都有亲戚结婚,忽然发现周围的小伙伴都结婚了,伯伯还说我这个是钱也输了,媳妇也没有,哈哈。
正月十二,去家里附近的餐馆过了个生。
预约到二月十五日考科目四,顺利通过科目四。
买的十六号晚上的票,领走前一天接到一个电话,五年来最大的好消息。 仿佛命运的转折点,这是转运的节奏么。
2016,很精彩。2017,我会有怎样的经历?
DNS(域名系统)是一种用于TCP/IP应用程序的分布式数据库,它提供主机名字和IP地址之间的转换及有关电子邮件的选路信息。
从应用的角度上看,对DNS的访问是通过一个地址解析器(resolver)来完成的。在Unix主机中,该解析器主要是通过两个库函数gethostbyname(3)和gethostbyaddress(3)来访问的。
DNS的名字空间和Unix的文件系统相似,也具有层次结构。下图显示了这种层次结构。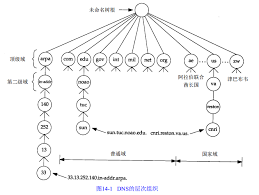
每个节点(上图中的圆圈)有一个至多63个字符长的标识。这棵树的树根是没有任何标识的特殊节点。命名标识中一律不区分大小写。命名树上任何一个节点的域名就是将从该节点到最高节点的域名串连起来,中间使用一个点“.”分割这些域名。域名树中的每个节点必须有一个唯一的域名,但域名树中的不同节点可使用相同的标识。
顶级域名被分为三个部分:
(1)arpa是一个用作地址到名字转换的特殊域
(2)7个3字符长的普通域,有些书也将这些域称为组织域。
(3)所有2字符长的域均是基于ISO3166中定义的国家代码,这些域被称为国家域,或地理域。 常见的me域名是前南斯拉夫地区西南部的国家黑山共和国(Montenegro,旧译“门的内哥罗”)的国家域名。现在也推出了一些新的域名,比如cloud顶级域名,属于国际通用新顶级域名,与.com、.net一样。然而.cloud域名行业特性更强,适合云计算设备、跳伞、天气预报等类型的企业或个人均可注册使用。
DNS的一个重要特征是DNS中域名中的授权,没有哪个机构来管理域名树中的每个标识,相反只有一个机构,即网络信息中心NIC负责分配顶级域和委派其他指定区域的授权机构。
一个独立管理的DNS子树称为一个区域。一个常见的区域是一个二级域,如noao.edu.许多二级域将它们的区域划分为更小的区域。例如大学可能根据不同的系来划分区域,公司可能根据不同的部门来划分区域。
一旦一个区域的授权机构被委派后,有它负责向该区域提供多个名字服务器。当一个新系统假如到一个区域中时,该区域的DNS管理者为该新系统申请一个域名和一个IP地址,并将它们加到名字服务器的数据库中。一个名字服务器负责一个或多个区域。一个区域的管理者必须为该区域提供一个主名字服务器和至少一个辅助名字服务器。主、辅名字服务器必须是独立和冗余的,以便当某个名字服务器发生故障不会影响该区域的名字服务。当一个新主机加入一个区域时,区域管理者将适当的信息(最少包括名字和IP地址)加入到运行在主名字服务器上的一个磁盘文件中,然后通知主名字服务器重新调入它的配置文件。辅名字服务器(通常是每隔3个小时)向主名字服务器询问是否有新数据。如果有新数据,则通过区域传送方式获得新数据。
当一个名字服务器没有请求的信息时,它必须与其它的名字服务器联系,这正是DNS的分布特性。然而,并不是每个名字服务器都知道如何同其他名字服务器联系。相反,每个名字服务器必须知道如何同根的名字服务器联系。所有的主名字服务器必须知道如何同根的名字服务器联系。跟服务器则知道所有二级域中的每个授权名字服务器的名字和位置(即IP地址)。这意味着这样一个反复的过程:正在处理请求的名字服务器与跟服务器联系,跟服务器告诉它与另一个名字服务器联系。
为了减少Internet上DNS的通信量,所有的名字服务器均使用高速缓存。
UDP是一个简单地面向数据报的传输层协议:进程的每个输出操作正好产生一个UDP数据报,并组装成一份待发送的IP数据报。这与面向流字符的协议不同,如TCP,应用程序产生的全体数据与真正发送的单个IP数据报可能没有什么联系。
UDP数据报封装成一份IP数据报,如下图所示。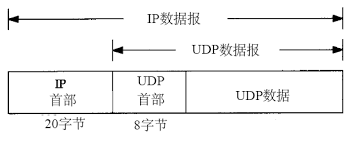
UDP不提供可靠性:它把应用程序传给IP层的数据发送出去,但是并不保证它们能到达目的地。
UDP首部的各字段如下图所示。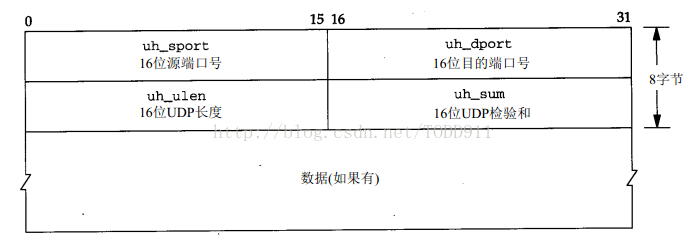
端口号表示发送进程和接收进程。
UDP长度字段指的是UDP首部和UDP数据的字节长度。该字段的最小值为8字节(发送一份0字节的UDP数据报是ok的)。
UDP校验和,UDP和TCP在首部中都有覆盖它们首部和数据的检验和。UDP的检验和是可选的,而TCP的检验和是必需的。UDP的数据报的长度可以为奇数字节,但是检验和算法是把若干个16bit字相加。解决方法是必要时在最后增加填充字节0,这只是为了检验和的计算(也就是说,可能增加的填充字节不被传送)。其次,UDP数据报和TCP段都包括一个12字节长的伪首部,它是为了计算检验和而设置的。UDP校验和是一个端到端的校验和。它由发送端计算,然后由接收端验证。其目的是为了发现UDP首部和数据在发送端到接收端之间发生的任何改动。不要完全相信数据链路(如以太网,令牌环等)的CRC检验,应该始终打开端到端的检验和功能。而且如果你的数据很有价值,也不要完全相信UDP和TCP的校验和,因为这些都是简单地检验和,不能检测出所有可能发生的差错。
来自客户的事UDP数据报。IP首部包含源端和目的端IP地址,UDP首部包含了源端和目的端的UDP端口号。
这个特性允许一个交互UDP服务器对多个客户进行处理。给每个发送请求的客户端发回应答。
一些应用程序需要知道数据报是发送给谁的,这要求操作系统从接收到的UDP数据报中将目的IP地址交给应用程序。不幸的是,并所有的操作系统都提供这个功能。
通常程序所使用的每个UDP端口都与一个有限大小的输入队列相联系。这意味着,来自不同客户的差不多同时到达的请求将由UDP自动排队。接收到的UDP数据报以其接收顺序交给应用程序(在应用程序要求交送下一个数据报时)。然而,排队溢出造成内核中的UDP模块丢弃数据报的可能性是存在的。
大多数UDP服务器在创建UDP端点时都使其本地IP地址具有通配符(wildcard)的特点。这就表明进入的UDP数据报如果其目的地为服务器端口,那么在任何本地接口均可接受到它。
当服务器创建端点时,它可以把其中一个主机本地IP地址包括广播地址指定为端点的本地IP地址。只有当目的IP地址与指定的地址相匹配时,进入的UDP数据报才能被送达这个端点。
有可能在相同的端口上启动不同的服务器,每个服务器具有不同的本地IP地址。但是,一般必须告诉系统应用程序重用相同的端口是没问题的。使用socket API时,必须指定SO_REUSEADDR选项。
大多数系统允许UDP端点对远端地址进行限制。这说明端点将只能接收特定IP地址和端口号的UDP数据报。
大多数的系统在某一时刻只允许一个程序端点与某个本地IP地址及UDP端口号关联。
在一个支持多播的系统上,这种情况将发生变化。多个端点可以使用同一个IP地址和UDP端口号,尽管应用程序通常必须告诉API是可行的。使用socket API时,必须指定SO_REUSEADDR选项。当UDP数据报到达目的IP地址为多播地址或广播地址,而且目的IP地址和端口号处有多个端点时,就向每个端点传送一份数据报的复制。但是如果UDP数据报到达的是一个单播地址,那么只向其中一个端点传送一份数据报的复制。选择哪个端点传送数据取决于各个不同的系统实现。